Month: June 2009
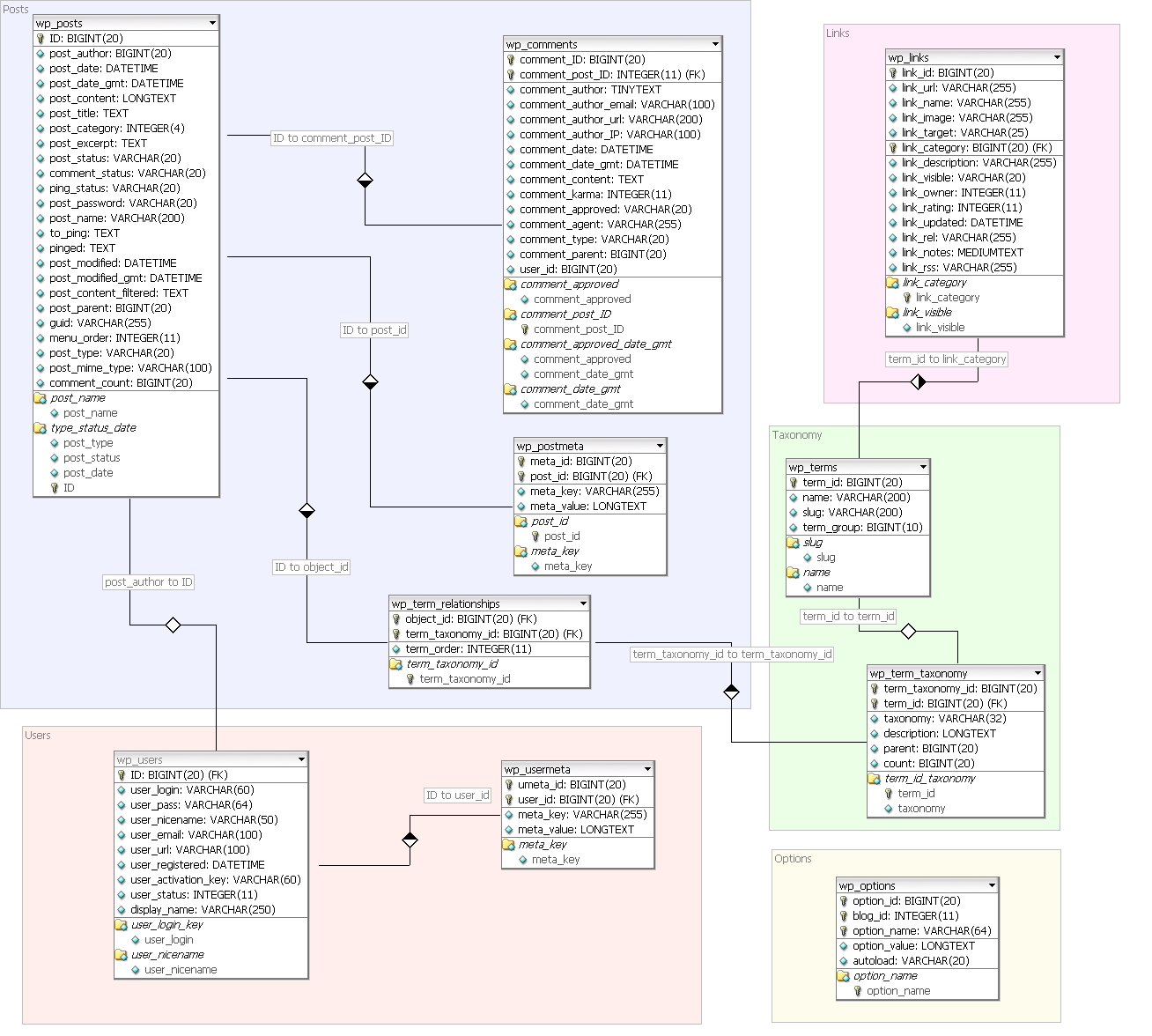
wordpress 的 schema
ver 2.7:
幾個查詢例:
SELECT m.* FROM wp_posts p , wp_postmeta m where p.id=m.post_id order by post_id desc SELECT tr.* FROM wp_posts p , wp_term_relationships tr where p.id=tr.object_id order by p.id desc SELECT p.id , w.* FROM wp_posts p , wp_term_relationships tr , wp_term_taxonomy t where p.id=tr.object_id and tr.term_taxonomy_id=t.term_taxonomy_id order by p.id desc SELECT p.id , w.* FROM wp_posts p , wp_term_relationships tr , wp_term_taxonomy t , wp_terms w where p.id=tr.object_id and tr.term_taxonomy_id=t.term_taxonomy_id and t.term_id = w.term_id order by p.id desc
gentoo emerge php options
2009.0630 Monster LAMP Pack:
取消 :
ncurses pdo readline spell
增加 :
ctype json sockets
berkdb gdbm
xmlreader xmlwriter
oci8-instant-client
USE="apache2 berkdb bzip2 calendar cjk cli crypt ctype curl gd gdbm hash iconv json mysql mysqli nls oci8-instant-client pcre reflection session simplexml sockets spl ssl tokenizer truetype unicode xml xmlreader xmlwriter zlib" emerge -av php
2009.0630 發現 wordpress code 裡面有用到 token_get_all ( tokenizer 所以不能取消)
Simple Monster Tracking System – step by step
mts.js , 網上範例很多 , 這個是基本型: ![]()
這段 code 前面就是一連串的組出 z 變數(包括 OS , BROWSER , SCREEN WIDTH/HEIGHT …) , 然後用一個小點透過 apache 的 log 記錄下來.
這個 apache 要裝 mod_setenvif 或 mod_rewrite modules , 在 apache config 中設定 只 log 特定的 tracking data.
SetEnvIf Request_URI /dot.gif MTS_icon
LogFormat "%{%Y-%m-%d}t , %{%H:%M:%S}t , %a , \"%q\" , \"%{Referer}i\" , \"%{User-agent}i\"" MTS_format
CustomLog "| /usr/sbin/cronolog /var/www/ts.monster.com.tw/log/access-%Y%m%d%H.log" MTS_format env=MTS_icon
引用例:

然後 apache log 會長這個樣子:

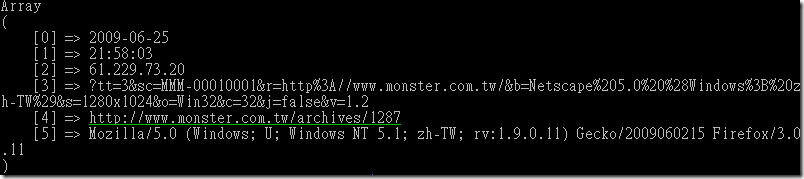
寫一段 PHP code:
$fp = fopen($mts_logfile,"r");
while ( $temp = fgetcsv($fp,$max_size) ) {
if ( count($temp)<1 ) continue;
print_r($temp);
}
fclose($fp);
結果就類似這樣:
再來就是處理 [3] 那邊的各種 data …
MySQL – Optimizing Database Structure
參考: http://dev.mysql.com/doc/refman/5.0/en/optimizing-database-structure.html
7.4.1. Make Your Data as Small as Possible
7.4.2. Column Indexes
7.4.3. Multiple-Column Indexes
7.4.4. How MySQL Uses Indexes
7.4.5. The MyISAM Key Cache
7.4.6. MyISAM Index Statistics Collection
7.4.7. How MySQL Opens and Closes Tables
7.4.8. Disadvantages of Creating Many Tables in the Same Database
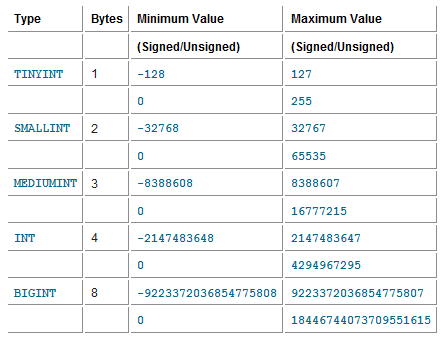
減少 record structure 的大小 – Numeric Types 參考表
(用 MEDIUMINT 3bytes 比 INT 4bytes 好 , 若資料內容不可能有負值那加上 UNSIGNED , 則數值範圍可多一倍!)
mysql index 的建立/使用 , Multiple-Column Indexes
http://dev.mysql.com/doc/refman/5.0/en/multiple-column-indexes.html
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
The name index is an index over the last_name and first_name columns. The index can be used for queries that specify values in a known range for last_name, or for both last_name and first_name. Therefore, the name index is used in the following queries:
SELECT * FROM test WHERE last_name='Widenius'; SELECT * FROM test WHERE last_name='Widenius' AND first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' AND (first_name='Michael' OR first_name='Monty'); SELECT * FROM test WHERE last_name='Widenius' AND first_name >='M' AND first_name < 'N';
However, the name index is not used in the following queries, 以下的 query 用不到 index —> 多重 index 有先後區別.
SELECT * FROM test WHERE first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' OR first_name='Michael';
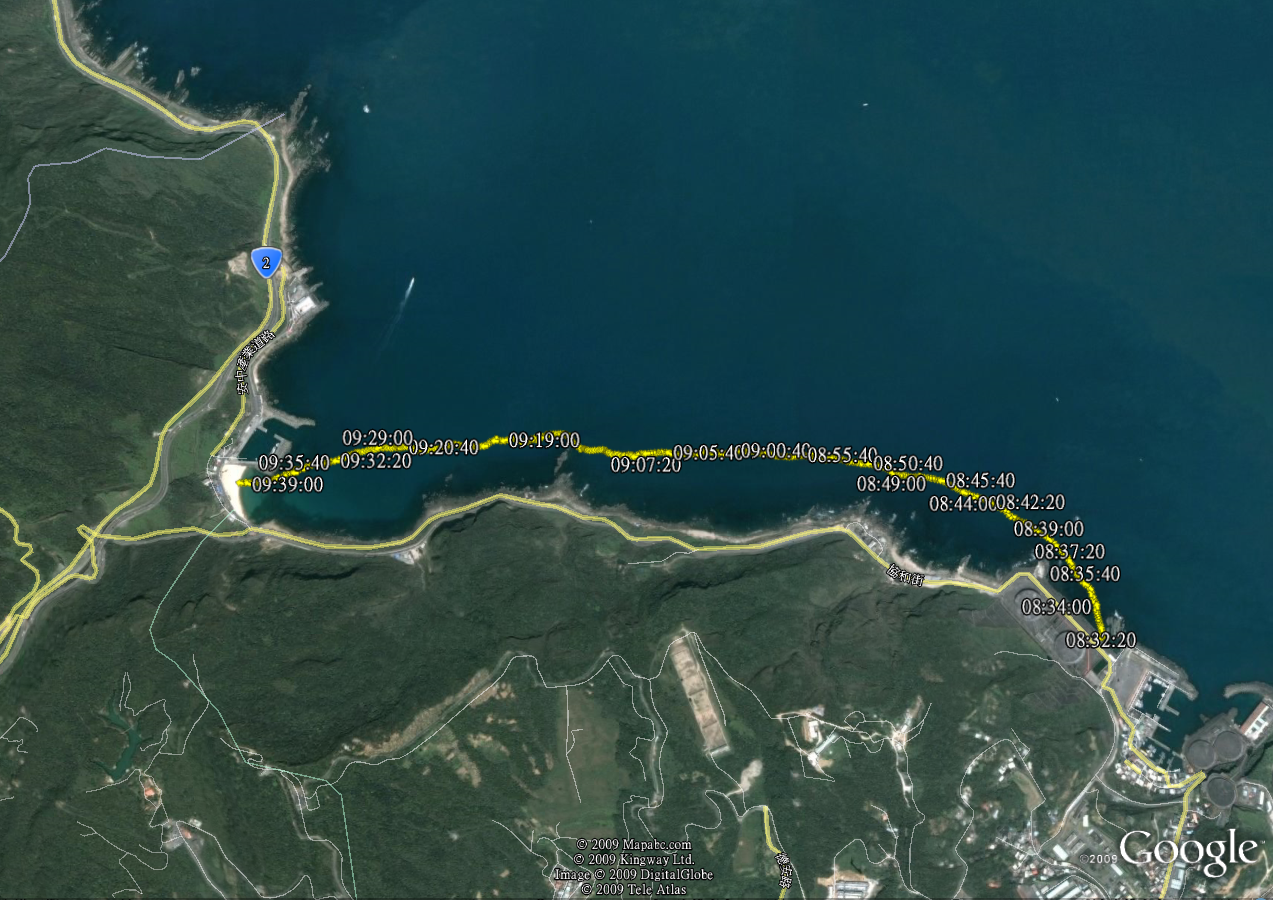
2009基隆市外木山海上4000公尺長泳
照這樣看, 不到 3000公尺呀??
今天游了 1小時8分 , 比去年快6分, 聽說今天海流是順的, 而且水母不多…
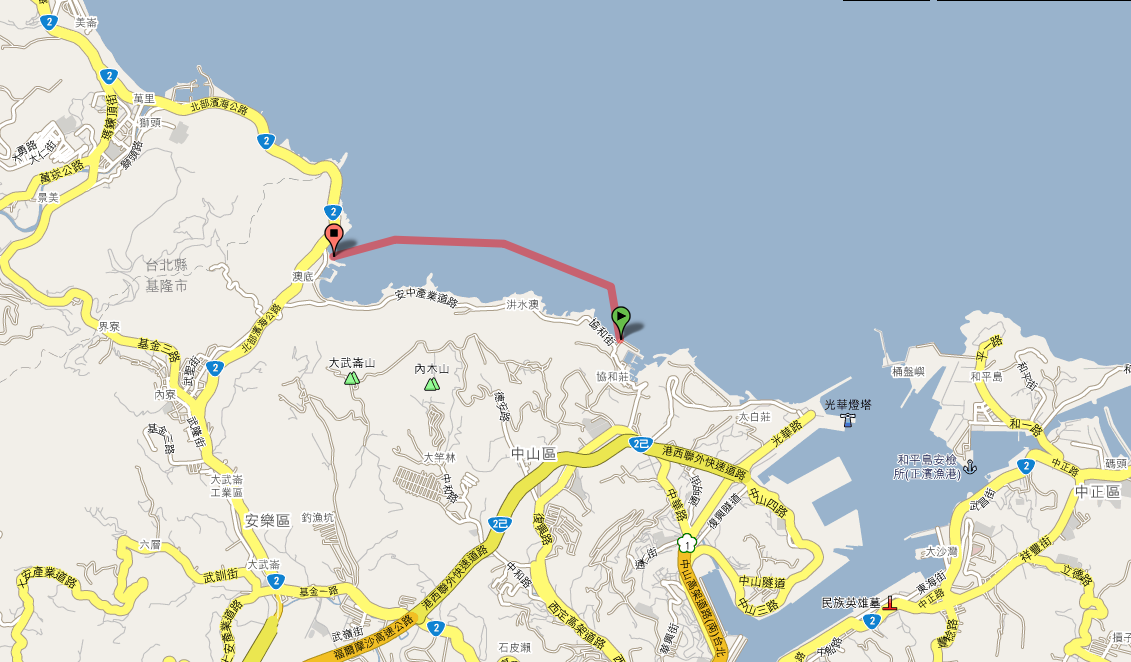
這是今天的路徑圖