SELECT * FROM SYS_USER PROCEDURE ANALYSE() \G;
URL : http://dev.mysql.com/doc/refman/5.0/en/procedure-analyse.html
From URL : http://anyall.org/blog/2009/04/performance-comparison-keyvalue-stores-for-language-model-counts/
| architecture | name | speed (tweets/sec) |
| in-memory, within-process | python dictionary | 2700 |
| on-disk, within-process | tokyo cabinet hashtable | 1400 |
| on-disk, within-process | berkeleydb hashtable | 340 |
| on-disk, over socket | tokyo tyrant, binary protocol | 225 |
| in-memory, over socket | memcached | 120 |
| in-memory, over socket | tokyo tyrant, memcached protocol | 85 |
| on-disk, over socket | tokyo tyrant, memcached protocol | 85 |
| on-disk, over socket | memcachedb | 0.5 |
memcache 的測試值跟我測得的數據接近(我用 100K 的 data測)
為了避免該資料不見, 搜藏/節錄一下重點:
More details on the options:
I can’t say this evaluation tells us too much about the server systems, since it’s all for a single process, which really isn’t their use case. It is interesting, however, to see that memcached’s plaintext protocol causing a big performance hit compared to a binary one. There’s a lot of talk and perhaps code for a binary memcached protocol, but I couldn’t find any docs suggesting whether it currently works. Tyrant seems to work great.
The biggest takeaway is that Tokyo Cabinet is awesome. It has very complete English language documentation — something sadly lacking in many otherwise fine Japanese open-source projects — and appears to be highly performant and very flexible. This presentation by its author (Mikio Hirabayashi) shows a pretty impressive array of different things the suite of packages can do. At the very least, I’ll probably abandon BerkeleyDB if Cabinet keeps working so well; and hopefully, distribution and remote access will be easy to add via Tyrant.
Final note: it’s interesting how many of these new low-latency datastore systems come out of open-sourced projects from social network companies. Tokyo Cabinet/Tyrant is from Mixi, a large Japanese social networking site; Cassandra is from Facebook; and Voldemort is from LinkedIn. (Hadoop HDFS, approximately from Yahoo, is another open-source non-rdbms distributed datastore, though it’s not really low-latency enough to be comparable.) Then there are lots of commercial low-latency and distributed systems for data warehousing (oracle greenplum vertica aster…) but all these large web companies seem happy open-sourcing their infrastructure. This is great for me, but sucks to be a database company.
若要大量 bluk 作 insert 動作前, 下 ALTER TABLE tbl_name DISABLE KEYS , 這樣可以讓 insert 加快,
但是作完 insert 後還是得 enable keys , 把 missing 的 indexs 補回來, 我想這時也是非常耗時間吧!!
另外 enable / disable keys 對於 mysql 5.1.1 以前的 partition table 沒有用
參考: http://dev.mysql.com/doc/refman/5.0/en/optimizing-database-structure.html
7.4.1. Make Your Data as Small as Possible
7.4.2. Column Indexes
7.4.3. Multiple-Column Indexes
7.4.4. How MySQL Uses Indexes
7.4.5. The MyISAM Key Cache
7.4.6. MyISAM Index Statistics Collection
7.4.7. How MySQL Opens and Closes Tables
7.4.8. Disadvantages of Creating Many Tables in the Same Database
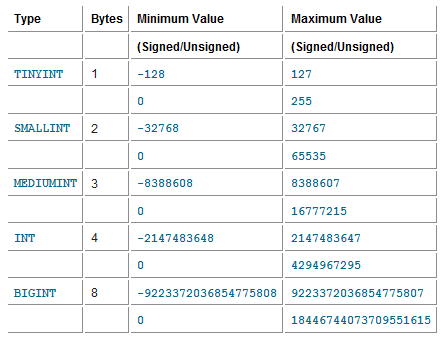
減少 record structure 的大小 – Numeric Types 參考表
(用 MEDIUMINT 3bytes 比 INT 4bytes 好 , 若資料內容不可能有負值那加上 UNSIGNED , 則數值範圍可多一倍!)
http://dev.mysql.com/doc/refman/5.0/en/multiple-column-indexes.html
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
The name index is an index over the last_name and first_name columns. The index can be used for queries that specify values in a known range for last_name, or for both last_name and first_name. Therefore, the name index is used in the following queries:
SELECT * FROM test WHERE last_name='Widenius'; SELECT * FROM test WHERE last_name='Widenius' AND first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' AND (first_name='Michael' OR first_name='Monty'); SELECT * FROM test WHERE last_name='Widenius' AND first_name >='M' AND first_name < 'N';
However, the name index is not used in the following queries, 以下的 query 用不到 index —> 多重 index 有先後區別.
SELECT * FROM test WHERE first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' OR first_name='Michael';
http://www.dba-oracle.com/t_sql_like_clause_index_usage.htm
Indexing when using the SQL "like" clause can be tricky because the wildcard "%" operator can invalidate the index. For example a last_name index would be OK with a "like ‘SMI%’" query, but unusable with "like ‘%SMI%’.
Solutions to this issue of a leading wildcard can be addressed in several ways::
Burleson Consulting 說:
These unnecessary full-table scans are a problem:
1. Large-table full-table scans increase the load on the disk I/O sub-system2. Small table full table scans (in the data buffer) cause high consistent gets and drive-up CPU consumption
非必要的 full-table-scans 造成幾個問題 : 大的資料表會增加 disk I/O , 小的資料表則是增加 CPU 消耗. 所以這個現象可以拿來觀察資料庫系統的問題點.