Month: June 2010
INTEL vs Transcend SSD little PK (LAB )
J神對於 SSD 的讀取速度特別著迷, 於是重金採購了兩款 performance 都不錯的 SSD 來 lab 一下, 以下就這次的 Result :
Jason Chen: 早上再做一次二顆 SSD 的 Xbench Disk Test , 這次是 Intel 勝出 Transcend 2.5" 32G SSD SLC Disk Test 73.82 Sequential 84.27 Uncached Write 104.16 63.95 MB/sec [4K blocks] Uncached Write 83.54 47.26 MB/sec [256K blocks] Uncached Read 48.92 14.32 MB/sec [4K blocks] Uncached Read 183.43 92.19 MB/sec [256K blocks] Random 65.67 Uncached Write 20.31 2.15 MB/sec [4K blocks] Uncached Write 107.89 34.54 MB/sec [256K blocks] Uncached Read 1982.02 14.05 MB/sec [4K blocks] Uncached Read 523.91 97.21 MB/sec [256K blocks] Intel X25-V 40G SSD MLC Disk Test 150.38 Sequential 97.48 Uncached Write 72.91 44.76 MB/sec [4K blocks] Uncached Write 72.35 40.94 MB/sec [256K blocks] Uncached Read 105.10 30.76 MB/sec [4K blocks] Uncached Read 251.19 126.25 MB/sec [256K blocks] Random 328.80 Uncached Write 389.34 41.22 MB/sec [4K blocks] Uncached Write 132.67 42.47 MB/sec [256K blocks] Uncached Read 2099.11 14.88 MB/sec [4K blocks] Uncached Read 631.72 117.22 MB/sec [256K blocks]




Maximum Availability Architecture – Oracle Streams Configuration Best Practices
Oracle doc PDF URL : http://dn.monster.tw/my/docs/oracle/MAA_10gR2_Streams_Configuration.pdf
Oracle® Streams Advanced Queuing User’s Guide and Reference
10g Release 2 (10.2) – http://download.oracle.com/docs/cd/B19306_01/server.102/b14257/toc.htm
sample memo: https://www.monster.com.tw/archives/2565
Oracle Maximum Availability Architecture – Overview – http://www.oracle.com/technology/deploy/availability/htdocs/maaoverview.html
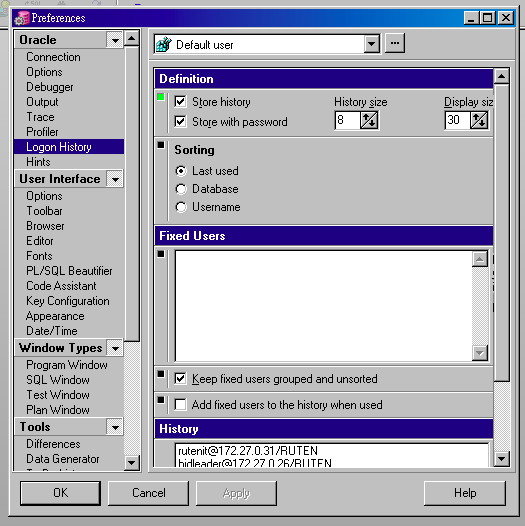
[設定/memo] PL/SQL Developer , PLSQL 免設 tnsname 檔的方法 , 儲存 password
在 Database 那格用這種格式: IP_ADDRESS/SERVICE_NAME

Question: google chart api
Open flash chart 有這樣的 數值 data 在線上

可是要怎樣 google chart 才會有呢?

google chart: http://code.google.com/intl/zh-TW/apis/chart/docs/chart_params.html
hunter 說:
http://code.google.com/intl/zh-TW/apis/chart/docs/chart_params.html#gcharts_data_point_labels
key / value database’ performance compare – 查詢 對照表效能 PK 賽
From URL : http://anyall.org/blog/2009/04/performance-comparison-keyvalue-stores-for-language-model-counts/
| architecture | name | speed (tweets/sec) |
| in-memory, within-process | python dictionary | 2700 |
| on-disk, within-process | tokyo cabinet hashtable | 1400 |
| on-disk, within-process | berkeleydb hashtable | 340 |
| on-disk, over socket | tokyo tyrant, binary protocol | 225 |
| in-memory, over socket | memcached | 120 |
| in-memory, over socket | tokyo tyrant, memcached protocol | 85 |
| on-disk, over socket | tokyo tyrant, memcached protocol | 85 |
| on-disk, over socket | memcachedb | 0.5 |
memcache 的測試值跟我測得的數據接近(我用 100K 的 data測)
為了避免該資料不見, 搜藏/節錄一下重點:
More details on the options:
- Python dictionary: defaultdict(int) is the simplest and most obvious implementation. It’s the baseline and the fastest. This is the best option for many types of experimental NLP code, since it can just be serialized to disk for use later. Only if you want many processes to build it concurrently and incrementally, or want many processes to access the model but not have to hold it in their own process space, do the other options start becoming relevant.
- BerkeleyDB: a well-known key/value store that I’ve used for a while. Unfortunately it’s been removed from the Python distribution, and there are often version hell issues every time I see people try to use it. (Every Linux/Unix seems to carry a different version, and they’re all not compatible with each other.)
- Tokyo Cabinet is a newish key/value store that has some impressive benchmarks. I just learned about it from Leonard’s post, and I also found it to be excellent. If Cabinet keeps being so awesome, I might never use BerkeleyDB again. (Though installation issues are worse than BerkeleyDB since it’s new enough to not be a common package; e.g. I found it on MacPorts but not Debian.)
- Memcached: The most standard in-memory key/value for use over sockets. Usually used for caching results from database queries for web applications — because in-memory caching is way faster than hitting disk on a database query. All data in a Memcached disappears if you turn it off. Clients talk to it via a plaintext protocol over sockets.
- The fact it was slower than the dictionary or BDB or Cabinet means that the communication overhead was high. The nice thing about Memcached for keeping running counts like this is that it should distribute well: have lots of different processes/machines processing data and asking a central Memcached cluster to increment counters. It might be a little unfair to compare Memcached performance to BerkeleyDB or Cabinet, since it’s designed for the situation of communicating with many clients at once. It’s usually considered a win if Memcached is faster than a parallel-ly accessed RDBMS, which is very much the case.
- I wonder how this architecture would compare to a Hadoop/HDFS/MapReduce for batch-job term counting performance. Jimmy Lin & other Maryland folks wrote an interesting report (2009) about using Memcached during a Hadoop job in a similar way for, among other things, this same language model use case. In general, lots of machine learning algorithms really don’t parallelize very well in the MapReduce architecture; parameter updates in Gibbs sampling, EM, and any online algorithm (e.g. SGD) are other examples. (An earlier paper on a better-than-mapreduce approach for EM parameters: Jason Wolfe et al. 2008; slides, paper.) A Memcached-like system could be a component of more client-server-ish parallel processing models for these use cases.
- Note of warning: there are actually 3 different Python libraries to talk to Memcached: (1) memcache.py aka python-memcached; (2) cmemcache which wraps the C library libmemcache, and (3) cmemcached.pyx aka python-libmemcached write wraps a different C library, libmemcached. For each one, the X in import X correlates quite poorly to the project’s name. Bleah. Option #3 seems newest, or at least has the best-maintained websites, so I used that.
- MemcacheDB is a BerkeleyDB-backed, Memcached-protocol server. Initially I had hoped it was just Memcached over BDB. Unfortunately this is clearly not the case. Its name is so similar yet its effectiveness is so different than Memcached! As Leonard points out, there are lots of half-assed solutions out there. It’s easy for anyone to create a system that works well for their needs, but it’s harder to make something more general.
- Tokyo Tyrant is a server implemented on top of Cabinet that implements a similar key/value API except over sockets. It’s incredibly flexible; it was very easy to run it in several different configurations. The first one is to use an in-memory data store, and communicate using the memcached protocol. This is, of course, *exactly* comparable to Memcached — behaviorally indistinguishable! — and it does worse. The second option is to do that, except switch to an on-disk data store. It’s pretty ridiculous that that’s still the same speed — communication overhead is completely dominating the time. Fortunately, Tyrant comes with a binary protocol. Using that substantially improves performance past Memcached levels, though less than a direct in-process database. Yes, communication across processes incurs overhead. No news here, I guess.
I can’t say this evaluation tells us too much about the server systems, since it’s all for a single process, which really isn’t their use case. It is interesting, however, to see that memcached’s plaintext protocol causing a big performance hit compared to a binary one. There’s a lot of talk and perhaps code for a binary memcached protocol, but I couldn’t find any docs suggesting whether it currently works. Tyrant seems to work great.
The biggest takeaway is that Tokyo Cabinet is awesome. It has very complete English language documentation — something sadly lacking in many otherwise fine Japanese open-source projects — and appears to be highly performant and very flexible. This presentation by its author (Mikio Hirabayashi) shows a pretty impressive array of different things the suite of packages can do. At the very least, I’ll probably abandon BerkeleyDB if Cabinet keeps working so well; and hopefully, distribution and remote access will be easy to add via Tyrant.
Final note: it’s interesting how many of these new low-latency datastore systems come out of open-sourced projects from social network companies. Tokyo Cabinet/Tyrant is from Mixi, a large Japanese social networking site; Cassandra is from Facebook; and Voldemort is from LinkedIn. (Hadoop HDFS, approximately from Yahoo, is another open-source non-rdbms distributed datastore, though it’s not really low-latency enough to be comparable.) Then there are lots of commercial low-latency and distributed systems for data warehousing (oracle greenplum vertica aster…) but all these large web companies seem happy open-sourcing their infrastructure. This is great for me, but sucks to be a database company.